SOURCE: Meta
Reading time: 3 minutes.
Summary:
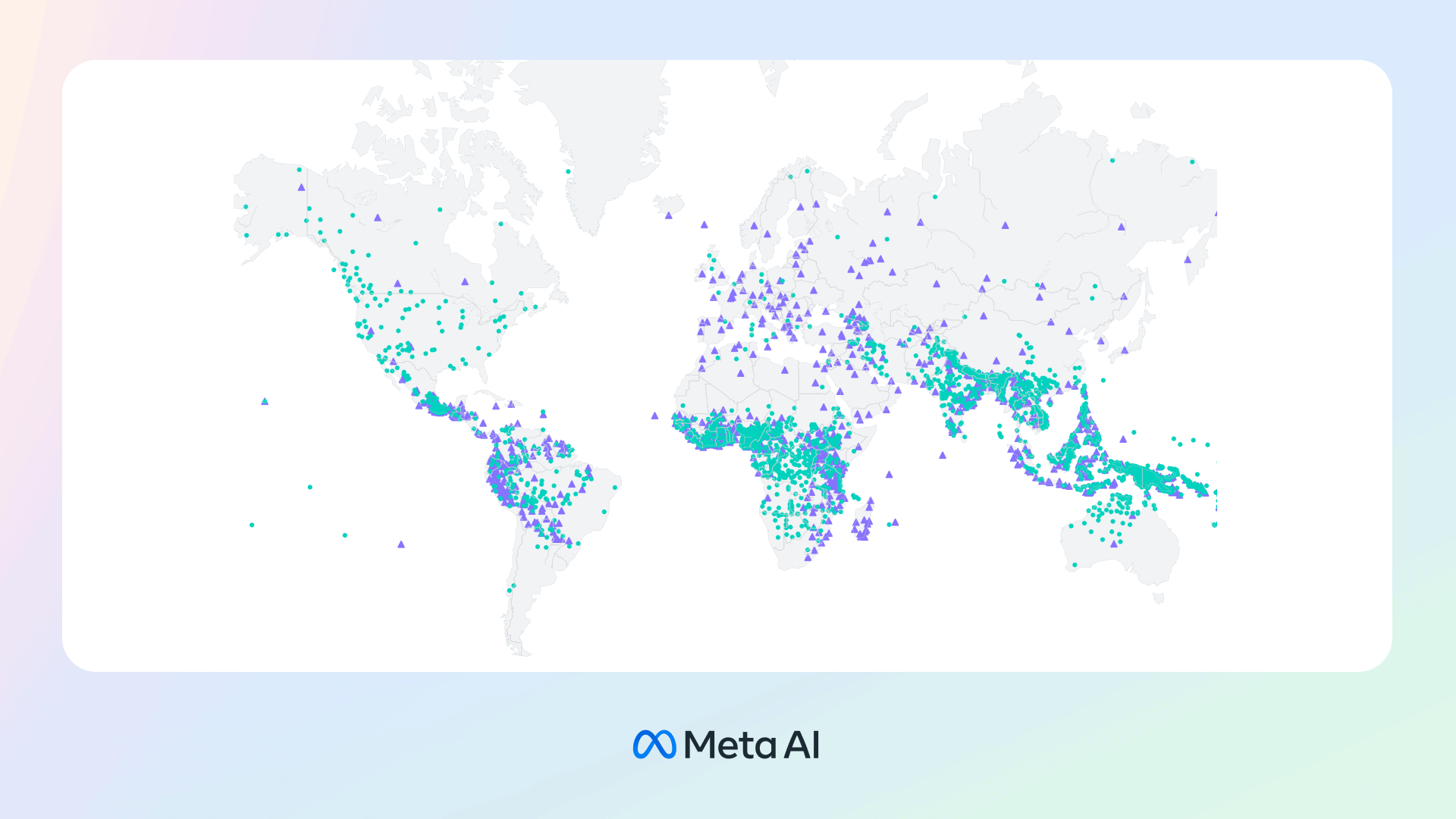
The Massively Multilingual Speech (MMS) project, developed by Meta, uses a model combining wav2vec 2.0 and a new dataset to improve speech recognition and production in over 1,100 languages. These efforts tackle the issue of many languages lacking the data necessary for effective machine learning models. Current speech recognition models only cover about 100 of the over 7,000 languages spoken worldwide, with half of these languages at risk of extinction. The MMS project sources its data from religious texts translated and recorded in various languages. Despite this data being domain-specific and primarily read by male voices, the models have demonstrated equal performance for male and female voices without biasing the language towards religious content. The project aims to expand language coverage, address dialect issues, and work towards a single model for all languages. By publicly sharing their models and code, Meta hopes to preserve language diversity and enhance global accessibility to information.